 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeMed-R1: Clinician-Audited Safety and Ethics Alignment for Medical Large Language Models
May 27, 2026Large language models(LLMs) increasingly match expert performance on licensing examinations, yet routine clinical use remains limited because governance requires auditable reasoning, safety and ethics alignment, and resilience to adversarial misuse. Here we present SafeMed-R1, trained with a traceable Clinical Trust Signals(CTS) pipeline that links each reasoning instance to clinician rubric scores and edit histories, and aligned through safety and ethics supervision and red team stress testing. SafeMed-R1 attains a macro-averaged accuracy of 79.6% across clinical benchmarks. Under adversarial safety testing, it shows the lowest aggregated risk and reduces unsafe outputs by about 3 to 5% relative to its baseline. In a paired expert study of 30 medication safety vignettes, SafeMed-R1 matches PGY1 and PGY2 residents on medical correctness and scores higher for medication safety, guideline consistency, and clinical usefulness. Collectively, these results suggest that clinician-audited supervision provenance, together with domain-tailored safety and ethics alignment, can strengthen governance-relevant evidence without relying on inference-time retrieval or citation grounding.
Interpreting V1 Population Activity via Image-Neural Latent Representation Alignment
May 05, 2026Understanding the neural mechanisms underlying visual computation has long been a central challenge in neuroscience. Recent alignment based approaches have improved the accuracy of decoding visual stimuli from brain activity, yet they provide limited insight into the neural computations that give rise to these improvements. To address this gap, we propose Dual-Tower Image-Neural Alignment (DINA), an interpretable contrastive framework for analyzing population level visual computations in primary visual cortex (V1). DINA jointly trains a biologically motivated dual-tower architecture that aligns visual stimuli and corresponding V1 population responses in a shared latent space at the level of intermediate feature maps, enabling both accurate decoding and direct access to interpretable feature maps. Evaluated on large-scale two-photon calcium imaging data from mouse V1, DINA achieves accurate neural-based decoding while revealing that decoding performance is primarily supported by coarse, low-level visual structure, rather than semantic category information or fine-grained details. Further analysis reveals that alignable feature maps emerge from multiple spatially distributed image regions, capturing both shape and texture cues, and are predominantly reconstructed by sparse subsets of strongly responsive neurons and their functional interactions. Together, these results confirm that, beyond enabling accurate decoding, DINA provides a principled framework for probing the computational mechanisms underlying visual processing in V1.
Leveraging Persistence Image to Enhance Robustness and Performance in Curvilinear Structure Segmentation
Jan 25, 2026Segmenting curvilinear structures in medical images is essential for analyzing morphological patterns in clinical applications. Integrating topological properties, such as connectivity, improves segmentation accuracy and consistency. However, extracting and embedding such properties - especially from Persistence Diagrams (PD) - is challenging due to their non-differentiability and computational cost. Existing approaches mostly encode topology through handcrafted loss functions, which generalize poorly across tasks. In this paper, we propose PIs-Regressor, a simple yet effective module that learns persistence image (PI) - finite, differentiable representations of topological features - directly from data. Together with Topology SegNet, which fuses these features in both downsampling and upsampling stages, our framework integrates topology into the network architecture itself rather than auxiliary losses. Unlike existing methods that depend heavily on handcrafted loss functions, our approach directly incorporates topological information into the network structure, leading to more robust segmentation. Our design is flexible and can be seamlessly combined with other topology-based methods to further enhance segmentation performance. Experimental results show that integrating topological features enhances model robustness, effectively handling challenges like overexposure and blurring in medical imaging. Our approach on three curvilinear benchmarks demonstrate state-of-the-art performance in both pixel-level accuracy and topological fidelity.
GROK: From Quantitative Biomarkers to Qualitative Diagnosis via a Grounded MLLM with Knowledge-Guided Instruction
Oct 05, 2025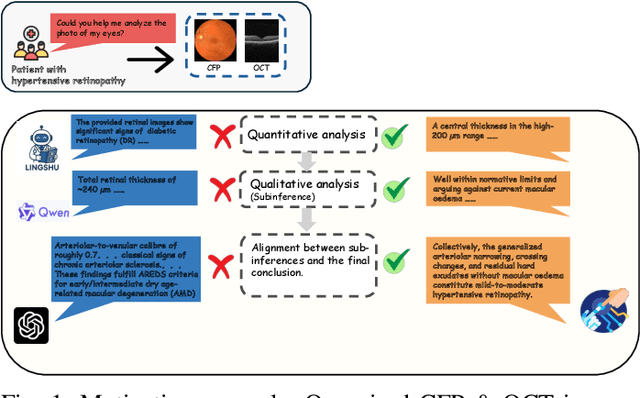
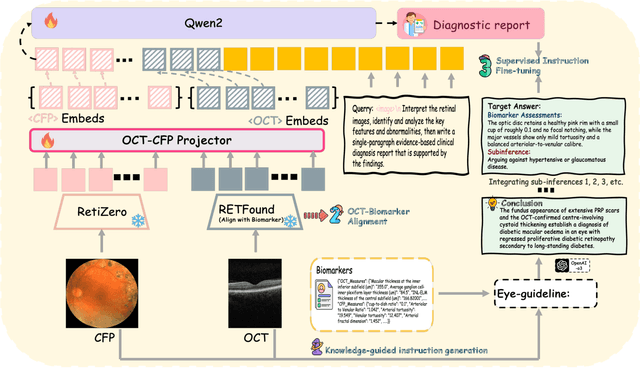
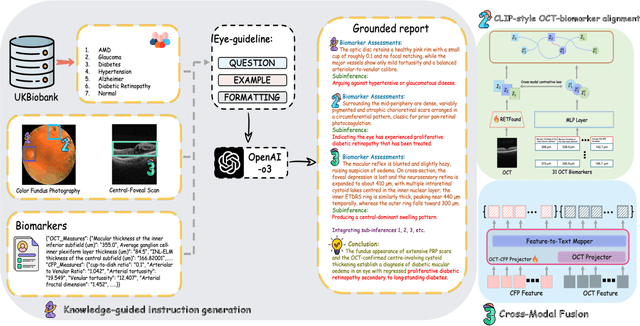

Multimodal large language models (MLLMs) hold promise for integrating diverse data modalities, but current medical adaptations such as LLaVA-Med often fail to fully exploit the synergy between color fundus photography (CFP) and optical coherence tomography (OCT), and offer limited interpretability of quantitative biomarkers. We introduce GROK, a grounded multimodal large language model that jointly processes CFP, OCT, and text to deliver clinician-grade diagnoses of ocular and systemic disease. GROK comprises three core modules: Knowledge-Guided Instruction Generation, CLIP-Style OCT-Biomarker Alignment, and Supervised Instruction Fine-Tuning, which together establish a quantitative-to-qualitative diagnostic chain of thought, mirroring real clinical reasoning when producing detailed lesion annotations. To evaluate our approach, we introduce the Grounded Ophthalmic Understanding benchmark, which covers six disease categories and three tasks: macro-level diagnostic classification, report generation quality, and fine-grained clinical assessment of the generated chain of thought. Experiments show that, with only LoRA (Low-Rank Adaptation) fine-tuning of a 7B-parameter Qwen2 backbone, GROK outperforms comparable 7B and 32B baselines on both report quality and fine-grained clinical metrics, and even exceeds OpenAI o3. Code and data are publicly available in the GROK repository.